Designing Planning Algorithms
for the Era of
Parallelism
One idea: the vectorizable planning kernel. Build the planner so its core data structure is a graph that GPUs store and compute natively. Then one Generate·Score·Reduce algebra generalizes it across the whole family.



The hardware stopped waiting for the algorithm.
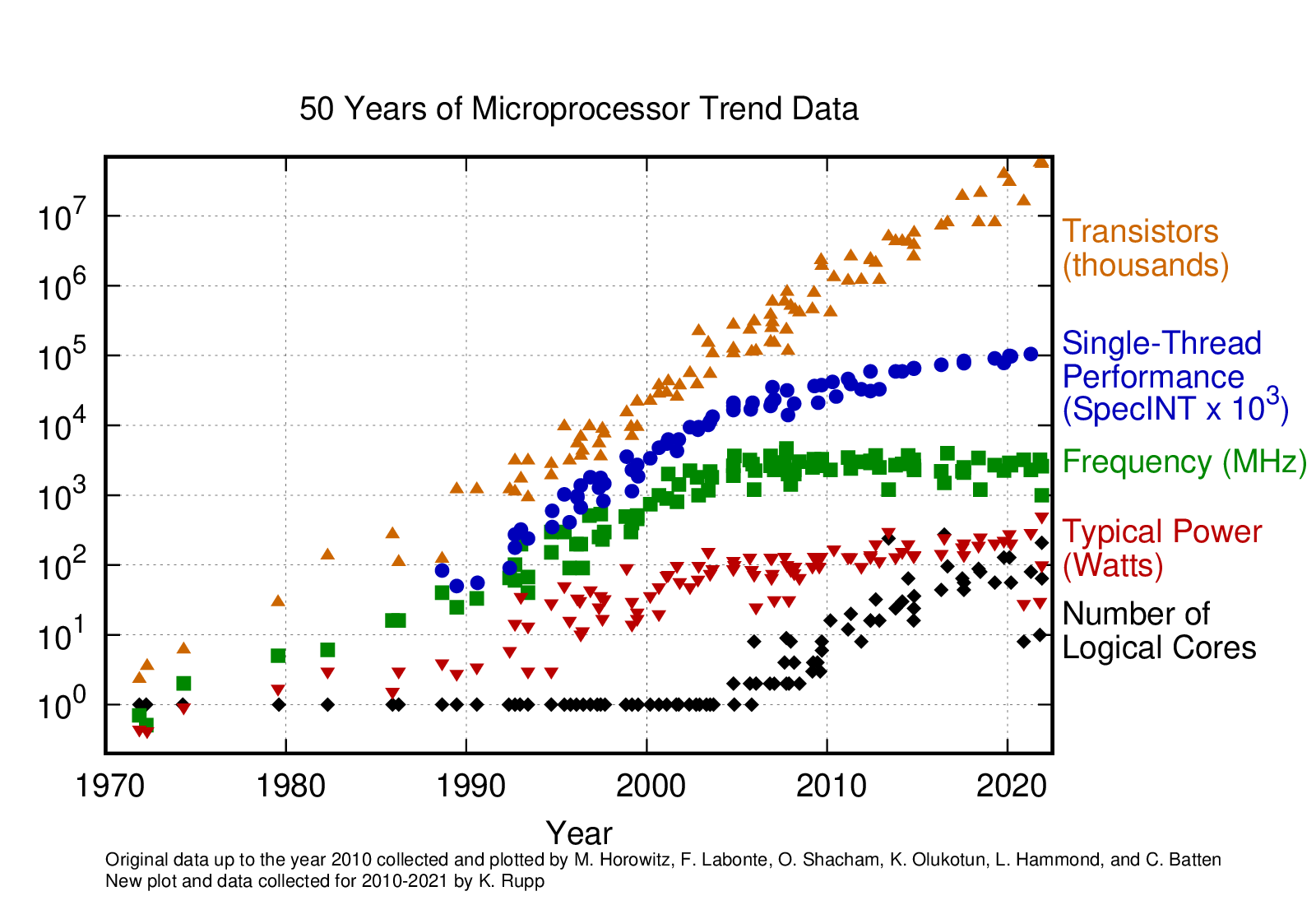
Parallel hardware is a design constraint, like dynamics, collision, or uncertainty.
In the spirit of Sutton, The Bitter Lesson (2019) & Hooker, The Hardware Lottery (CACM 2021): methods that ride general, scalable compute win.
What changed
- Performance now comes from more cores, not faster ones. GPUs and SIMD CPUs (one instruction, many data lanes) are now commodity for robotics.
- ML stacks (JAX · XLA · MuJoCo XLA · Triton) made dense, batched compute the default.
- Classical sampling-based planners (OMPL, the MoveIt default) are serial pointer-chasing, so most of this hardware sits idle.
A vectorizable planning kernel exposes all three. Its core data structure is a tensor: a dense, regular array of numbers that GPUs store and compute directly. That is this talk's answer to the RoboARCH question of matching the algorithm to the hardware.
The usual question is “how do I parallelize my planner?”
A more useful one: “what planner would I write if parallelism were the primitive?”
1 · Generate
Make many similar subproblems visible at once, as one batched object.
2 · Score
Evaluate every candidate independently. Keep the geometry and logic; do not flatten into brute force.
3 · Reduce
End with one structured reduction: min, Sinkhorn, expectation, score, DP.
The design move: make the algorithm itself vectorizable. The algebra that generalizes it, Generate · Score · Reduce, comes after we build it concretely.
Two ways to use parallel hardware: vectorize the kernels, or vectorize the algorithm.
VAMP · FCIT*
ICRA 2024 · 2025
Parallelize the kernels inside an existing planner. VAMP SIMD-vectorizes collision checking; FCIT* evaluates all pairwise edges cheaply to drop nearest-neighbor queries. 35 µs median, ~25 kHz on one core (7-DoF Panda); FCIT* first fully-connected a.s.-optimal.
cuRobo · pRRTC · cpRRTC
2023–2025
Parallelize the kernels inside an existing planner. pRRTC / cpRRTC do SIMT collision checking and parallel tree expansion for RRT-Connect. cuRobo ~60× vs CPU; pRRTC ~1.4× slower than GTMP, ~3× slower than VAMP-RRTC; cpRRTC up to 165× constrained.
GTMP · MPOT · CLOT · MTP · MPD
RA-L · NeurIPS · ICRA · ICLR · T-RO · 2023–2026
Make the planning algorithm itself the vectorizable object. The graph is a tensor, so search becomes native GPU math. GTMP: 1000 paths in 4.6 ms.
Both directions are winning, and they meet. Recent work vectorizes the kernels; this talk designs the algorithm to be vectorizable, then plugs those kernels in as connectors. Underneath sits batched, differentiable simulation (Isaac Gym, MuJoCo MJX/XLA, Brax); the benchmark of record is MotionBenchMaker.
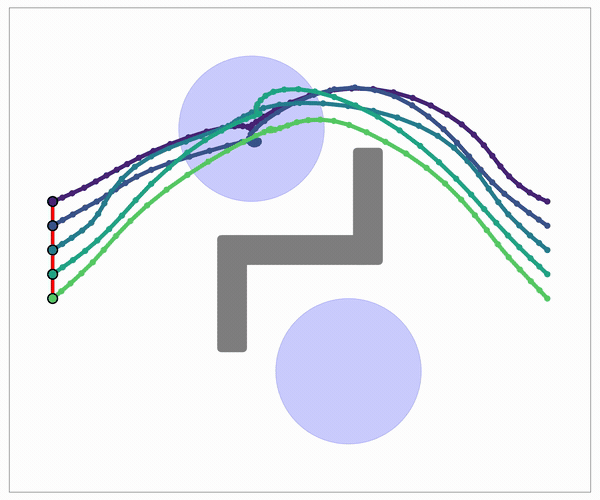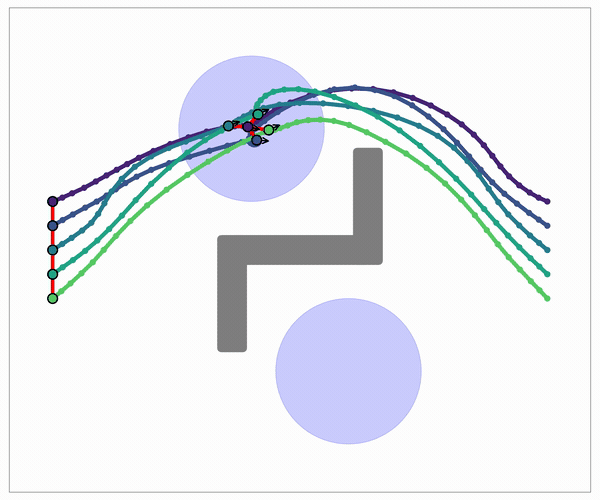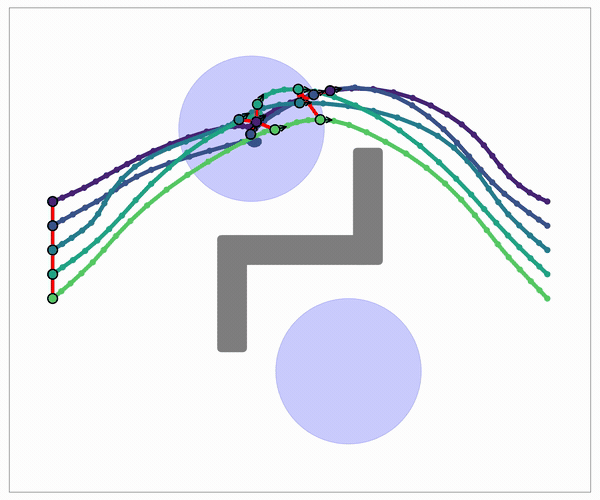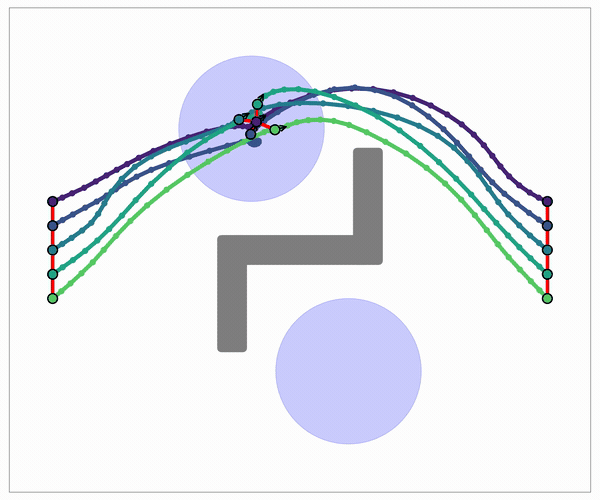
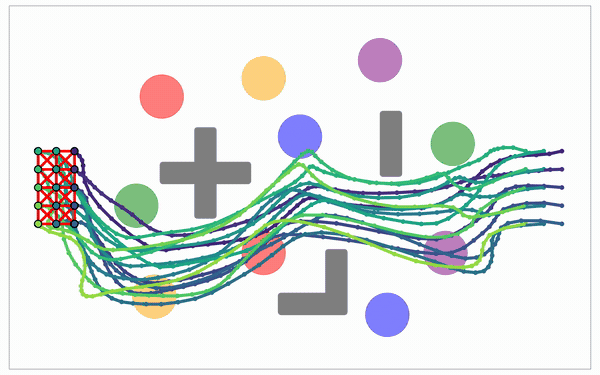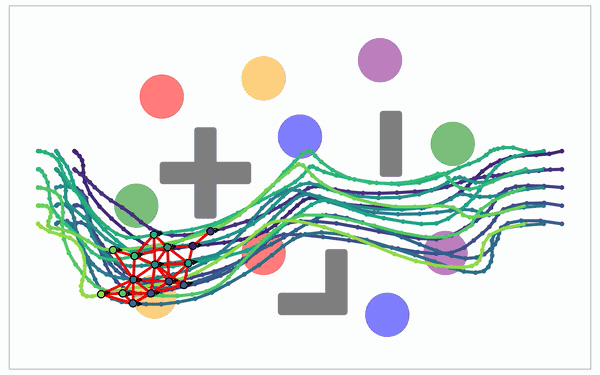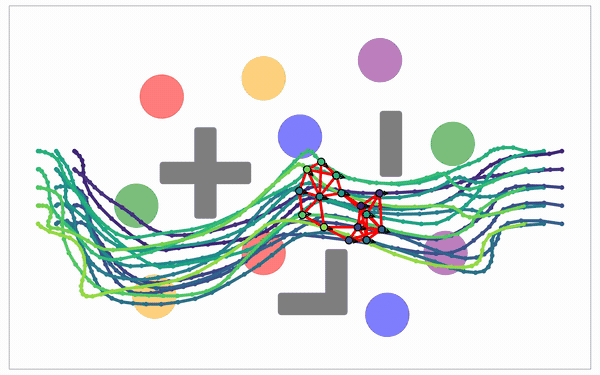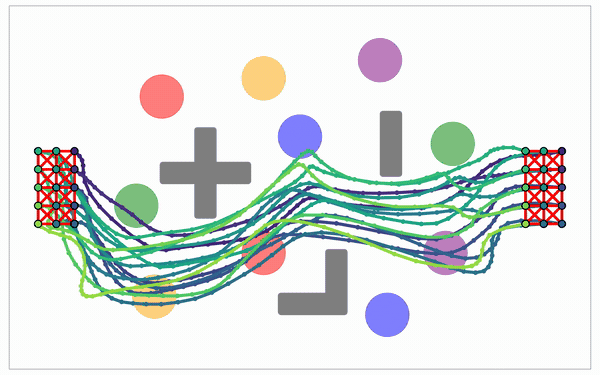
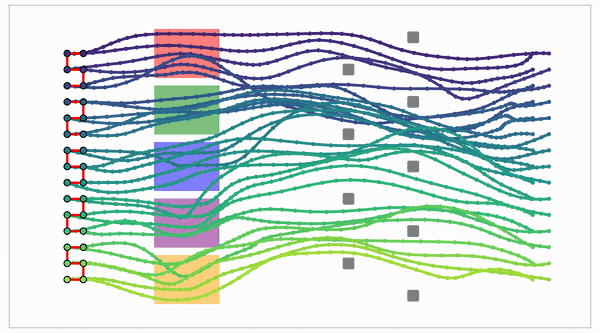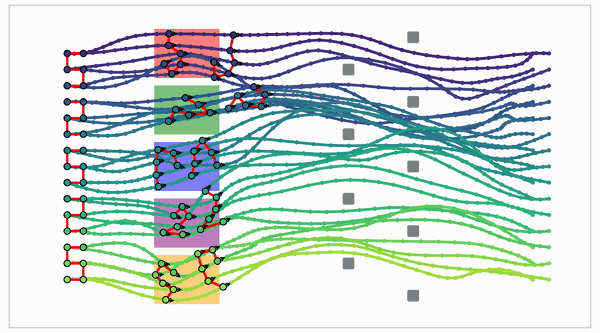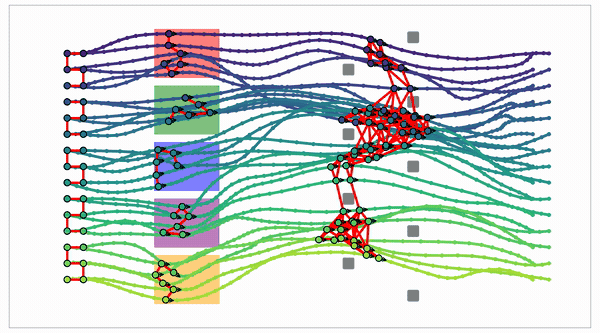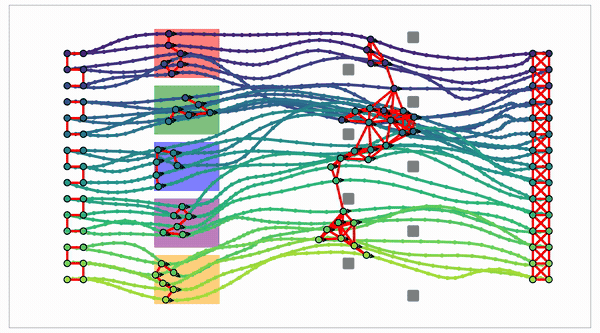
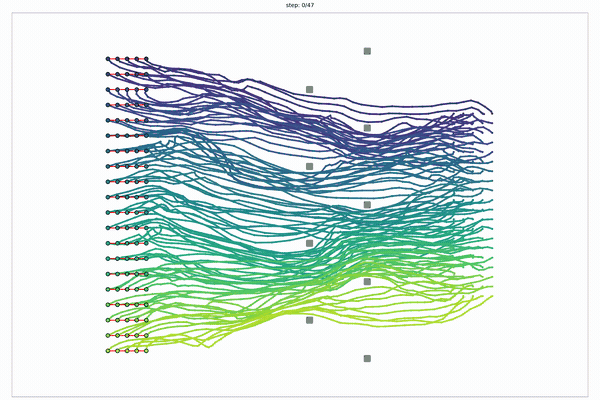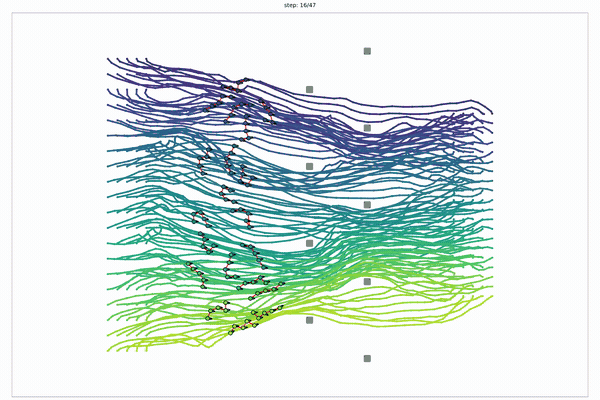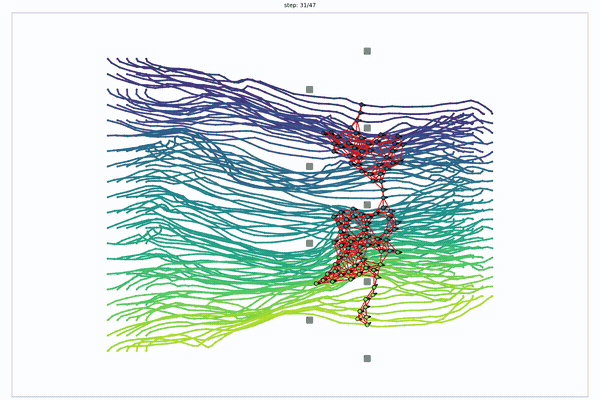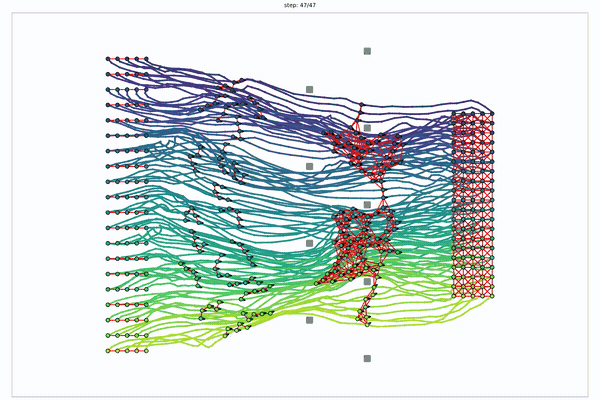
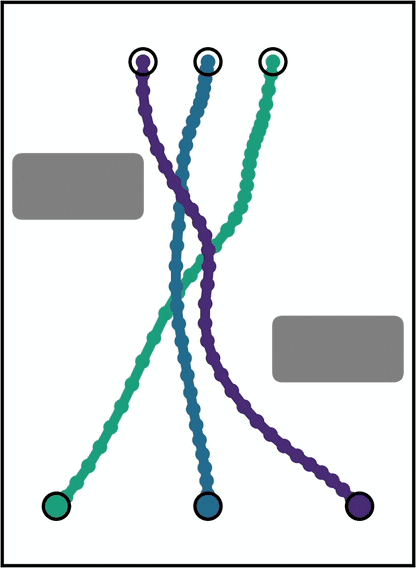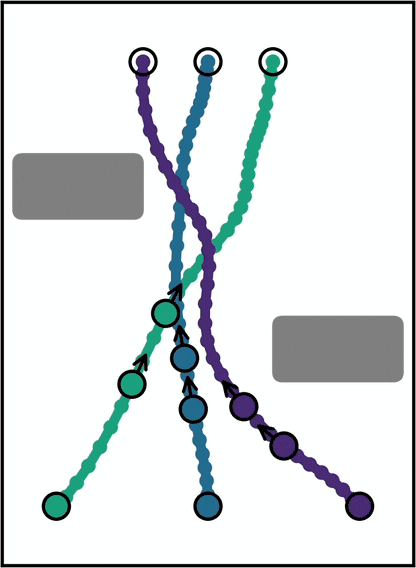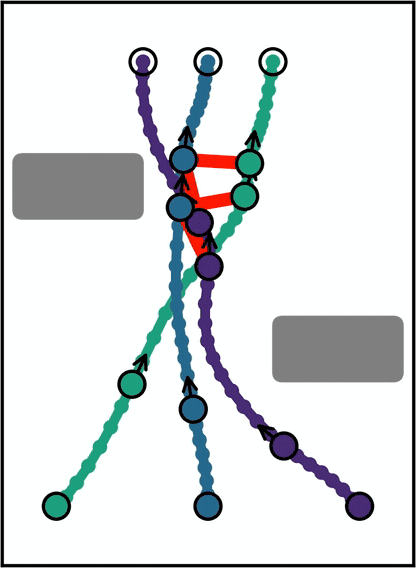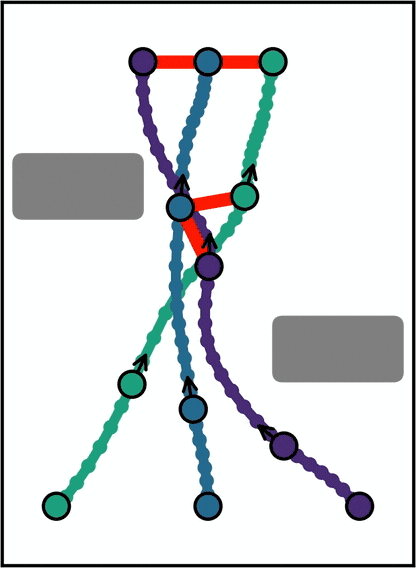
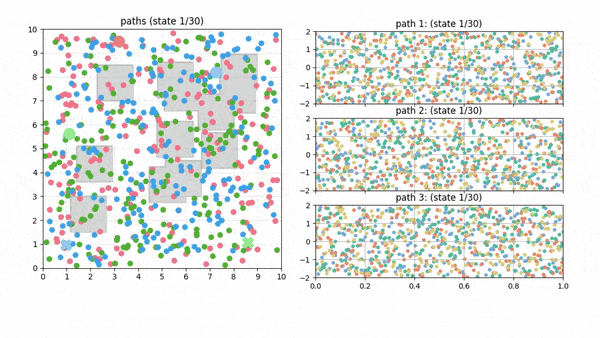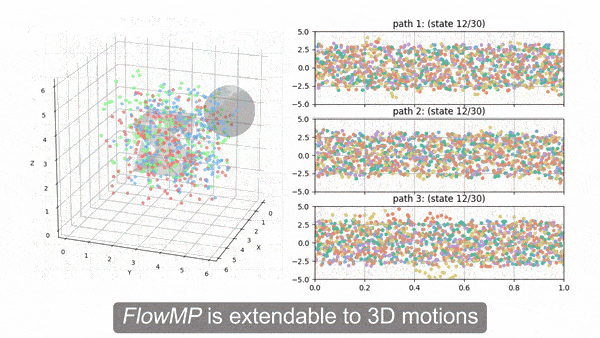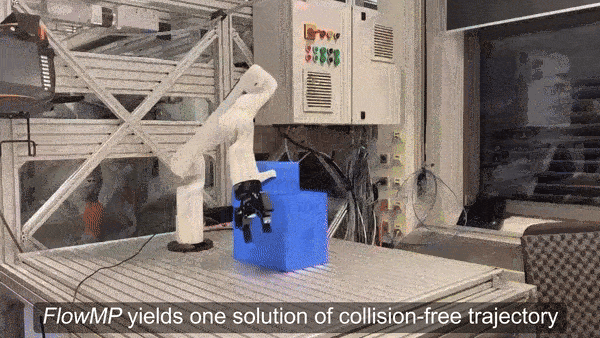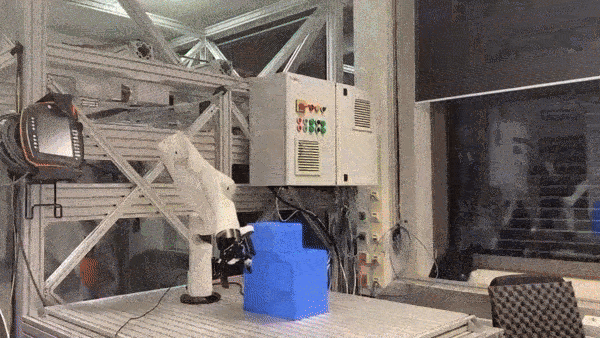
Global search becomes a layered random multipartite graph.
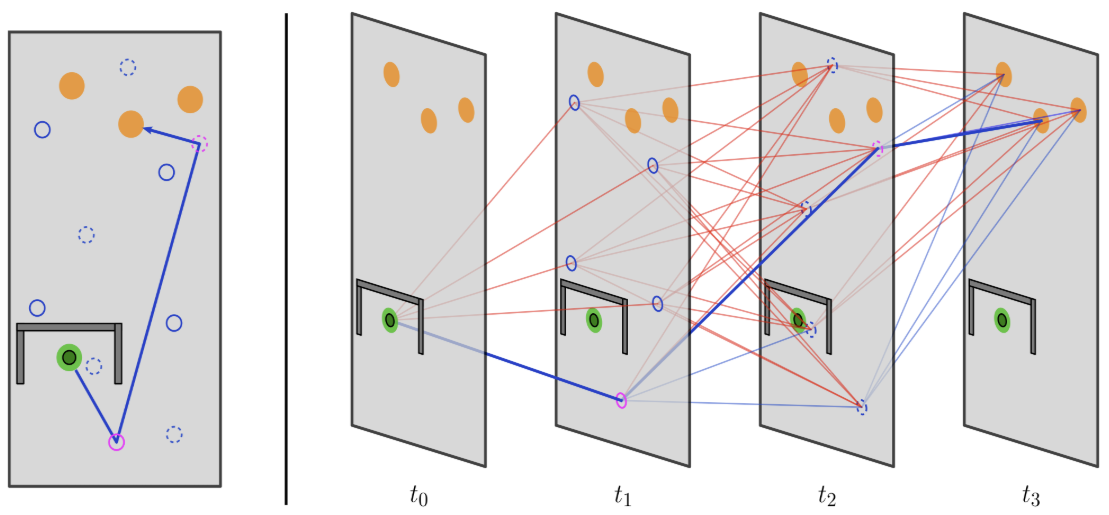
The idea: the graph is a tensor
- Sample N points in each of M layers.
- Evaluate adjacent-layer edges in batch.
- Run finite-horizon value iteration on the layered DAG.
One graph holds several different route families (paths you can't bend into one another without crossing an obstacle). So diversity is built into the data structure, not added in a later step. Swap the straight edge for a smooth Akima connector and the same kernel returns smooth plans, at no extra cost.
teal · tensor / batch axes sage · value / cost orchid · operator / reducer rose · this‑talk highlight
The Bellman backward pass is a tropical (min-plus) matrix–vector product.
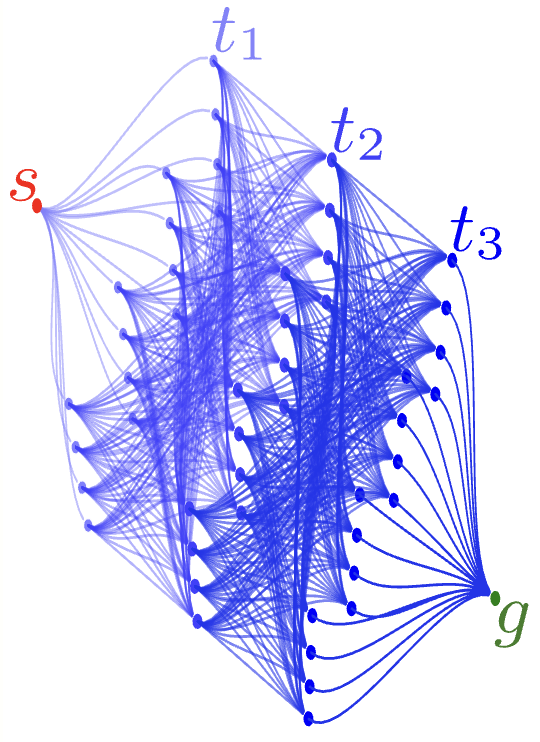
Edge count
Single start/goal, complete adjacent-layer connectivity. Every adjacent-layer pair is an independent local subproblem.
Backward DP · the Reduce step
A batched min-reduction over the next-layer axis: $J_m = C_m\boxtimes J_{m+1}$. In tropical (min-plus) algebra, “add” means take the minimum and “multiply” means add costs. So it runs like a dense matrix–vector product, the regular work a GPU is fastest at.
The edge is a pluggable connector, including a smooth Akima edge that stays in-kernel.
Reach $\Lambda$: at budget $s$, with confidence $1-\tau$, the connector succeeds on local hops up to length $\ell$.
This builds on OMPL; it does not replace it. Eighteen years of
sampling-based engineering (OMPL since 2008, 40+ planners, the MoveIt default, Kavraki & Moll)
becomes the per-edge Generate+Score, while the tropical Reduce stays fixed. GTMP consumes connectors; it does not compete with
them.
VAMP‑RRTC · pRRTC · AORRTC · FCIT* · cuRobo · CHOMP · MPD
The field is converging: OMPL 2.0 plans to add SIMD/GPU acceleration (VAMP). The vectorizable graph is where the connectors plug in.


Smooth planning, no extra solve: swap the straight edge for an Akima spline.
Akima splines are local: each segment uses only its neighbors. So there is no global linear solve to serialize, unlike a natural cubic spline, which couples every segment. They stay C¹ and overshoot-free, so each edge stays an independent subproblem, and a smooth plan falls out of the same Reduce at no extra cost.
Anytime should not conflate diversity and optimality.
Mode RR · diversity
- Fix $(M,\,N,\,s)$; draw independent graph realizations.
- Top-$B$ class-indexed elite archive.
- Diversity = coverage of distinct route families: paths you cannot bend into one another without hitting an obstacle (distinct homotopy classes).
geometric rate, so almost-sure coverage as $K\to\infty$ (2nd Borel–Cantelli)
Mode AO · cost
- Grow $M_\nu,\,N_\nu \to \infty$; keep $s$ fixed.
- Informed samples inside the ellipsoid that shrinks around the best path so far.
- Reuse + prune edges; AO$^\star$-style convergence to $c^\star$.
optimality by contracting support
Two schedules of the same reducer: diversity repeats generation, optimality enriches it.
Competitive on feasibility, with batch throughput few methods reach.
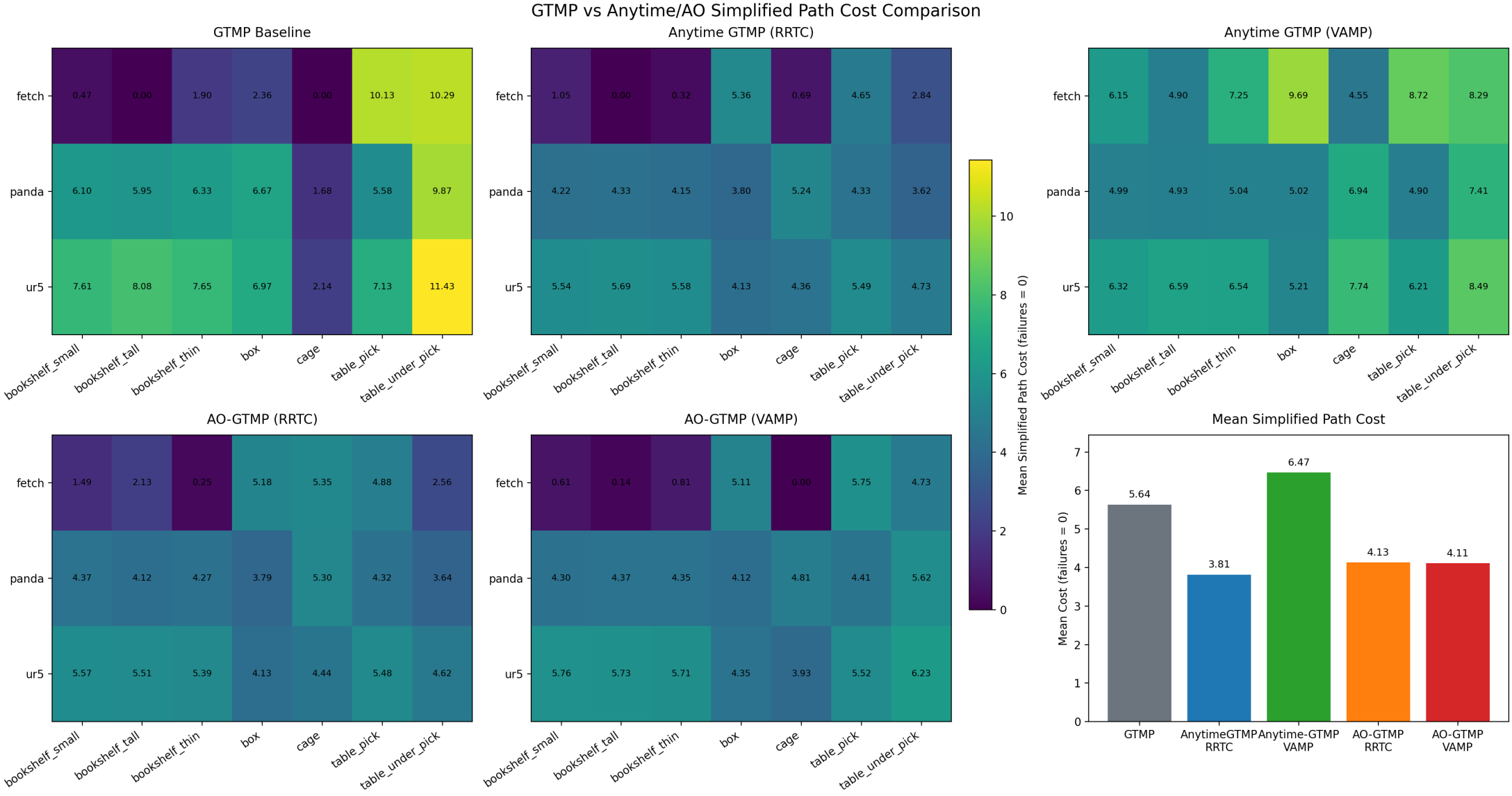
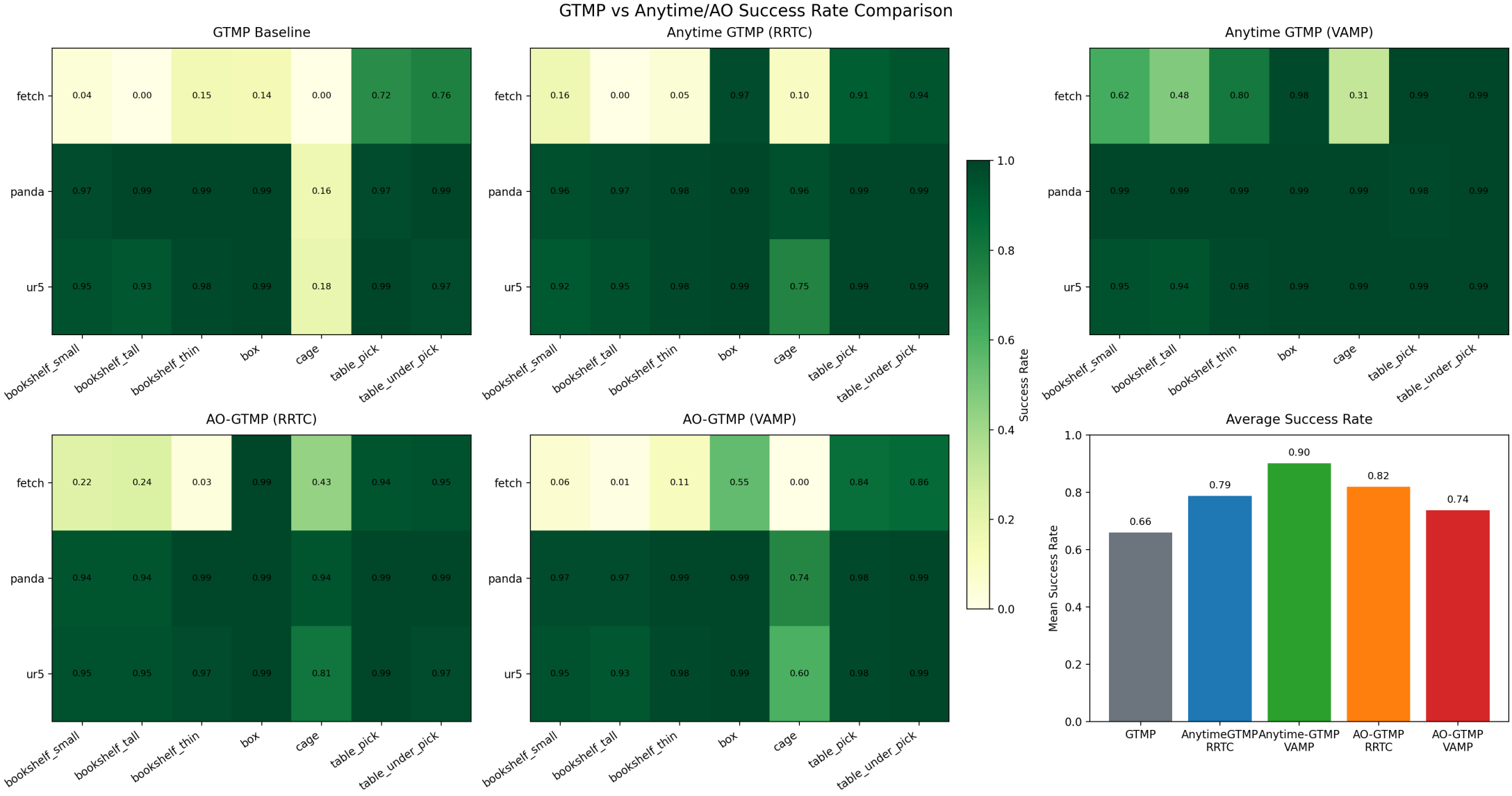
anytime-GTMP charts: results from a manuscript under preparation.
500 parallel Panda instances in ~0.3 ms via JAX
vmap on RTX 3090.
The planner's data structure is a graph that parallel hardware stores and computes, not only a path generator.
A 3-D array of candidate vertices: $M$ layers, $N$ samples per layer, each a point in $\mathbb{R}^d$. The graph is laid out as a tensor that GPUs read directly, so search becomes a native operation.
The planner's data structure is a graph that parallel hardware stores and computes, not only a path generator.
What this buys you
- Many candidate futures in one object, so diversity comes built in.
- Local work distributed across SIMT lanes.
- Global decisions recovered by reductions (DP, Sinkhorn, prune).
- Theorems and kernels describe the same object.
This batched object is a vectorizable planning kernel: a graph whose natural operations are GPU kernels. Building it is the Generate stage.
Every planner here is Generate → Score → Reduce.
Three verbs. Each is a typed map; their composition is the planner.
Every planner here is Generate → Score → Reduce.
$$\textbf{Planner}=\textcolor{#8a3f9c}{\textstyle\bigoplus}\,\circ\,\textcolor{#557a3a}{s}\,\circ\,\textcolor{#2f7d8a}{\mathcal{G}_\theta}.\qquad\small\text{Different planners are different semiring choices for one skeleton.}$$
Five planners, one kernel: they differ only in the reduction.
Generate and Score are shared. A planner only picks the reducer $\oplus$ over the semiring $(\mathbb{S},\oplus,\otimes)$ (an algebra with one combine op $\oplus$ and one chain op $\otimes$, in effect a swappable arithmetic). One compiled kernel spans all five, with a single temperature knob $\lambda$ sliding between them.
One kernel schedule for all five planners.
Reduction-invariance
Every $\oplus_\lambda$ is associative, so all five share one iteration space, one memory layout, and one $O(\log B)$ reduction tree. One compiled template instantiated by swapping the combine op.
What actually differs
- min is one comparator; soft-min spends $\exp/\log$ on the SFU (with a max-shift for stability).
- Register pressure and occupancy differ, so “one template” $\ne$ identical wall-clock.
- $\min$ returns an index (argmin path); soft-min returns a distribution.
The proof object and the compute object are the same: the semiring is both the algebra in the theorem and the reduction in the kernel. Invariant skeleton, method-specific arithmetic. Next: the per-method work and depth.
Associativity buys an $O(\log B)$ reduction tree. That is the architecture payload.
Embarrassingly-parallel Score gives $W=|B|\,\text{cost}(s)$ at fixed depth; an associative $\oplus$ folds it in $O(\log B)$. Available parallelism $W/D$ sets the ceiling; realized speed is then capped by bandwidth and occupancy.
| Method | Semiring $(\oplus,\otimes)$ | Work $W$ | Depth $D$ |
|---|---|---|---|
| GTMP | $(\min,+)$ | $\Theta(MN^2)$ | $\Theta(M\log N)$ |
| MPOT | soft-min, $+$ | $\Theta(T\,nm)$ | $\Theta(T\log n)$ |
| CLOT | OT $\otimes$ STL min/max | $\Theta(R\,(Tnm{+}|\Phi|T))$ | $\Theta(R\log nm)$ |
| MTP | expectation | $\Theta(BH)$ | $\Theta(H{+}\log B)$ |
| MPD | score | $\Theta(KB\,c_\theta)$ | $\Theta(K\,d_\theta)$ |
Every method shares the depth signature $D=(\text{sequential scan})+O(\log B)$. The scan length is the number an architect should optimize.
Warm the temperature: swap GTMP's hard min for a soft-min.
GTMP selects one vertex. Relax the selection and the same DP becomes differentiable transport.
Sinkhorn Step: the soft-min relaxation of the tropical DP.
Optimal transport (OT) = the cheapest plan to move mass from one set of points to another; entropic OT = a soft, temperature-blurred version; Sinkhorn = repeated row/column rescaling of a matrix that solves it. $\lambda\to 0$ recovers GTMP: the transport plan concentrates on the min-cost vertices, so soft selection becomes hard selection.

Sinkhorn is matrix-scaling: the densest GPU-friendly inner loop.
Gradient-free because the search set is a polytope.
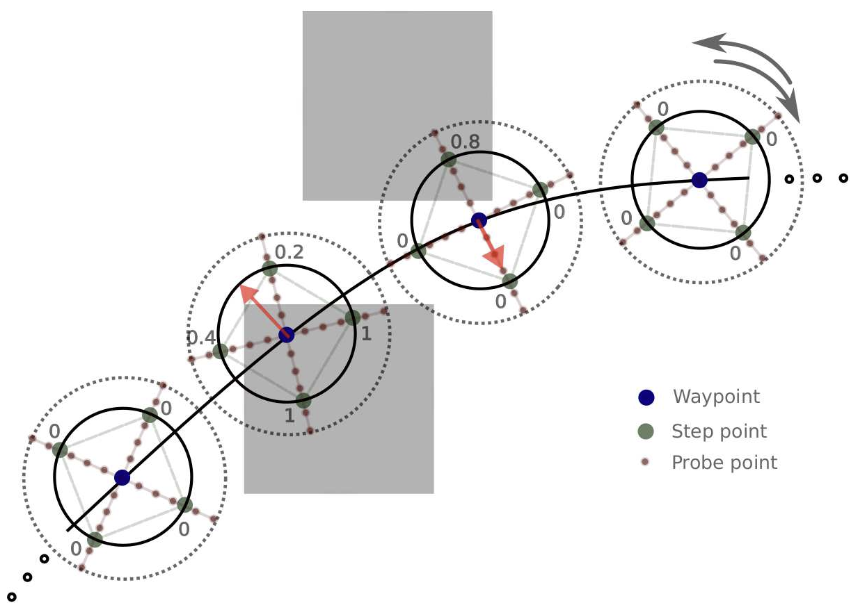
The inner loop: matrix scaling
Two GEMV + two divides per iteration, shared across the whole batch. No gradients, no factorizations. The densest GPU-friendly inner loop.
Choosing the polytope probes ($D_P\subset\mathbb{S}^{d-1}$, $m$ directions) is the Generate stage; this scaling is the Reduce.
From a 2-D probe to whole-body mobile manipulation.
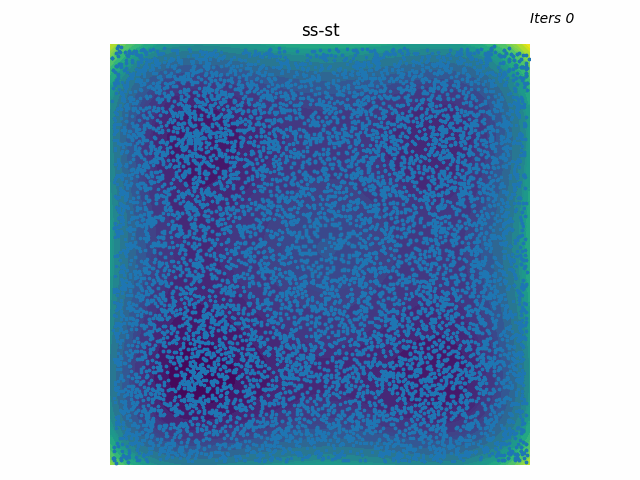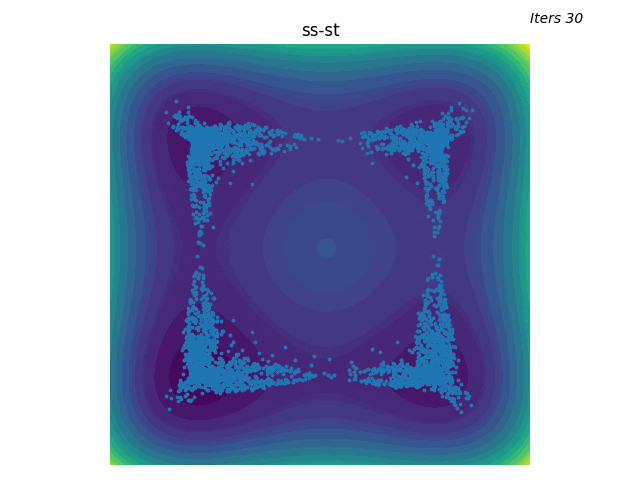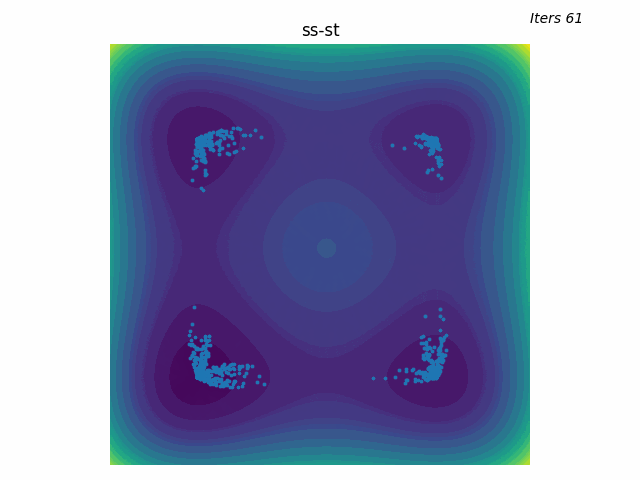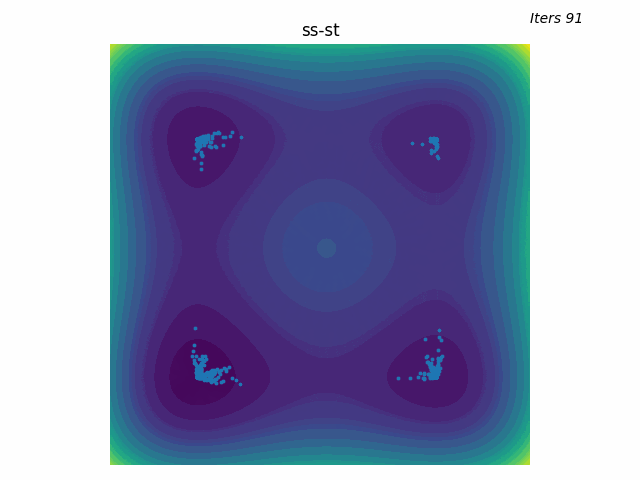
Same reducer as GTMP, one temperature warmer. The batch axis is the trajectory; the polytope is the per-waypoint candidate set.
From single-robot transport to multi-robot, temporal-logic-coupled transport.
Multi-robot STL tasks
Signal Temporal Logic (STL): timed rules like “hold the formation between 8 and 15 s.” Here, that means collision avoidance, dynamic feasibility, relative formation, connectivity, and bounded-time goals $G_I$, $F_I$, $U_I$.
How
GPU-parallel, gradient-free zero-order Sinkhorn Steps over batches of system-wide smooth trajectories.
Scale
Few seconds for small teams; tractable for 100+ robots.
One Sinkhorn kernel, reused per robot: CLOT scales 5 → 15 → 30 → 100 robots.
$$\underbrace{\mathbb{R}^{\textcolor{#ff217d}{B}\times\textcolor{#2f7d8a}{n}\times \textcolor{#2f7d8a}{m}}}_{B\approx10^{3}\ \text{trajectories batched / robot}}\ \times\ \underbrace{\textcolor{#ff217d}{R}\ \text{robots}}_{\text{planned sequentially, search-ordered}}\qquad\small\text{same kernel }K_{ij}=e^{-C_{ij}/\lambda}$$
CLOT reuses MPOT's per-robot Sinkhorn batch unchanged, then sequences robots in a dependency order via hybrid search. The kernel never changes; the parallel batch is the ~10³ trajectories per robot, not the robots themselves. All-simulation scaling study (each trajectory color is a distinct robot's path); the 3-UAV result (story 8/8) is the hardware validation.
Start from the MPOT cost …
One robot, one transport cost. Now couple many robots under temporal logic.
STL robustness, collective cost, connectivity: all batchable.
STL robustness (how strongly the spec is satisfied)
Parse-tree decomposition: a batched min/max reduction over time slices, tropical again.
Collective cost
Task robustness + obstacle penalty + inter-robot penalty, all dense per timestep, summed over robots.
Connectivity
Algebraic connectivity $\lambda_2$ (Fiedler value) of the inter-robot Laplacian $L(t)$: $\lambda_2>0\Leftrightarrow$ the team is connected — a smooth, batchable stand-in for the yes/no connectivity test, with $\lambda_2$ itself as the robustness margin.
The Sinkhorn step is untouched. The cost surface gets richer; the update stays a dense regular kernel.
Three reducers, one stack: sequence · optimal transport · STL min/max.
CLOT is GSR nested three deep. Each level is its own Generate·Score·Reduce; the semirings compose without changing the kernel schedule.
CLOT treats the robot planning order as part of the search.
Hybrid search node
$\nu$ indexes both the discrete planning sequence and the continuous candidate-trajectory set, so the search is over both at once.
Value function
Coverage minus accumulated cost plus back-propagated feedback $\psi(\nu)$; the weight $\eta>0$ trades cost against coverage (the decay $\gamma\in(0,1)$ discounts back-prop by tree distance).
Scalability and reliability on STL-coupled multi-robot tasks.
| Method | Success N=12 | Time N=12 |
|---|---|---|
| CLOT (ours) | 1.00 | 20.3 s |
| MPOT | 0.10 | 26.5 s |
| FSOT | 0.70 | 19.8 s |
| CONS | 0.00 | n/a |
| MICP / NLP / CBS | 0.00 | n/a |
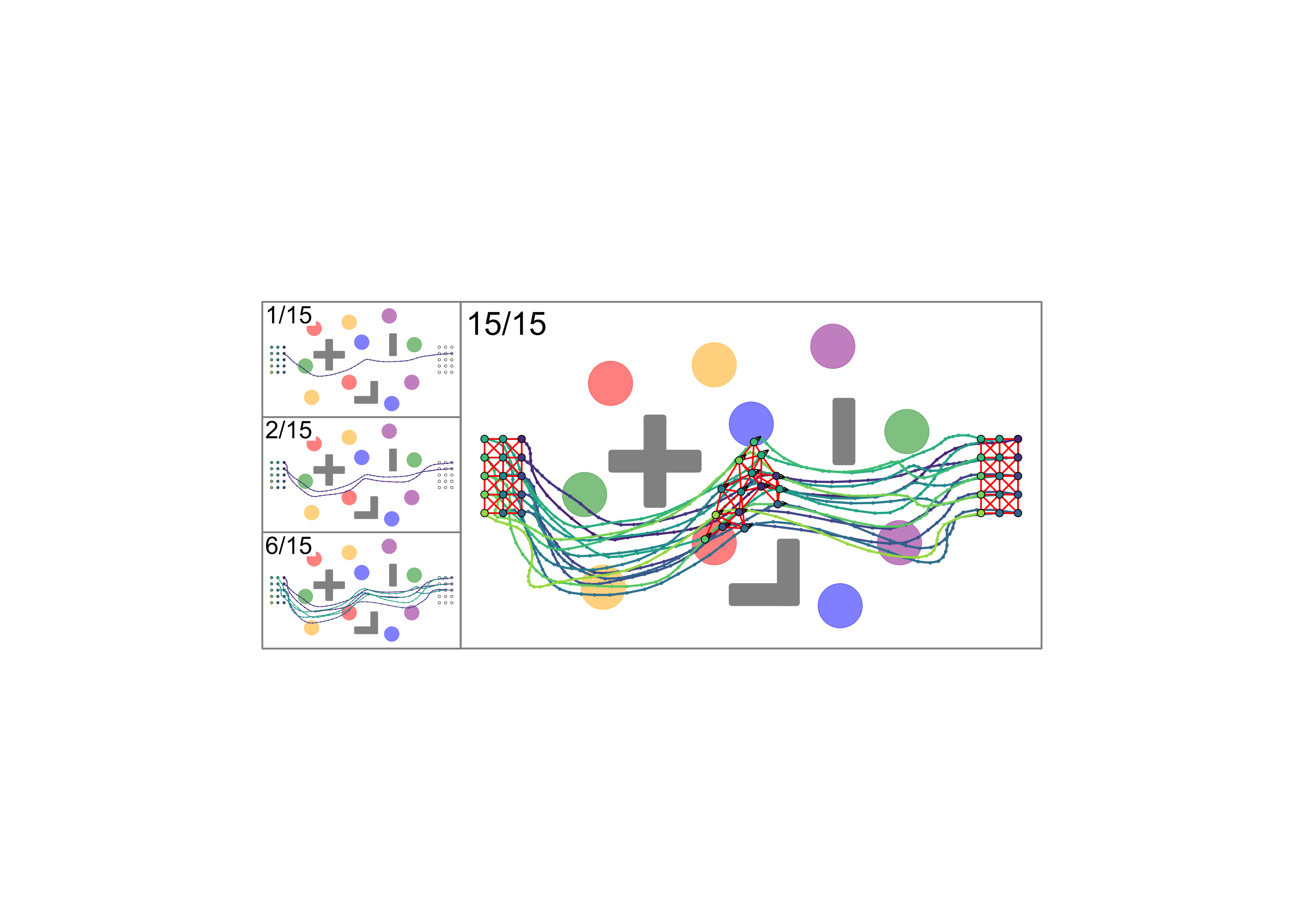
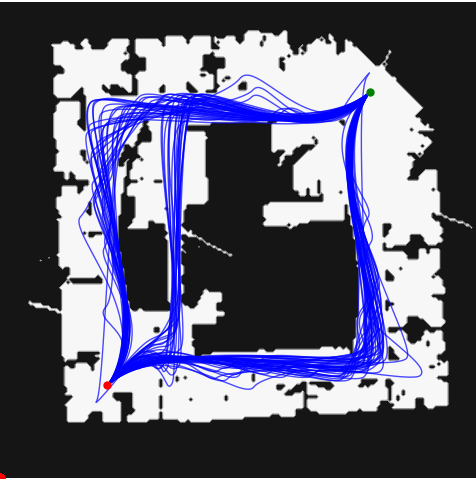
3-UAV hardware: planned in 2.91 s, formation tracked to ±0.1 m.
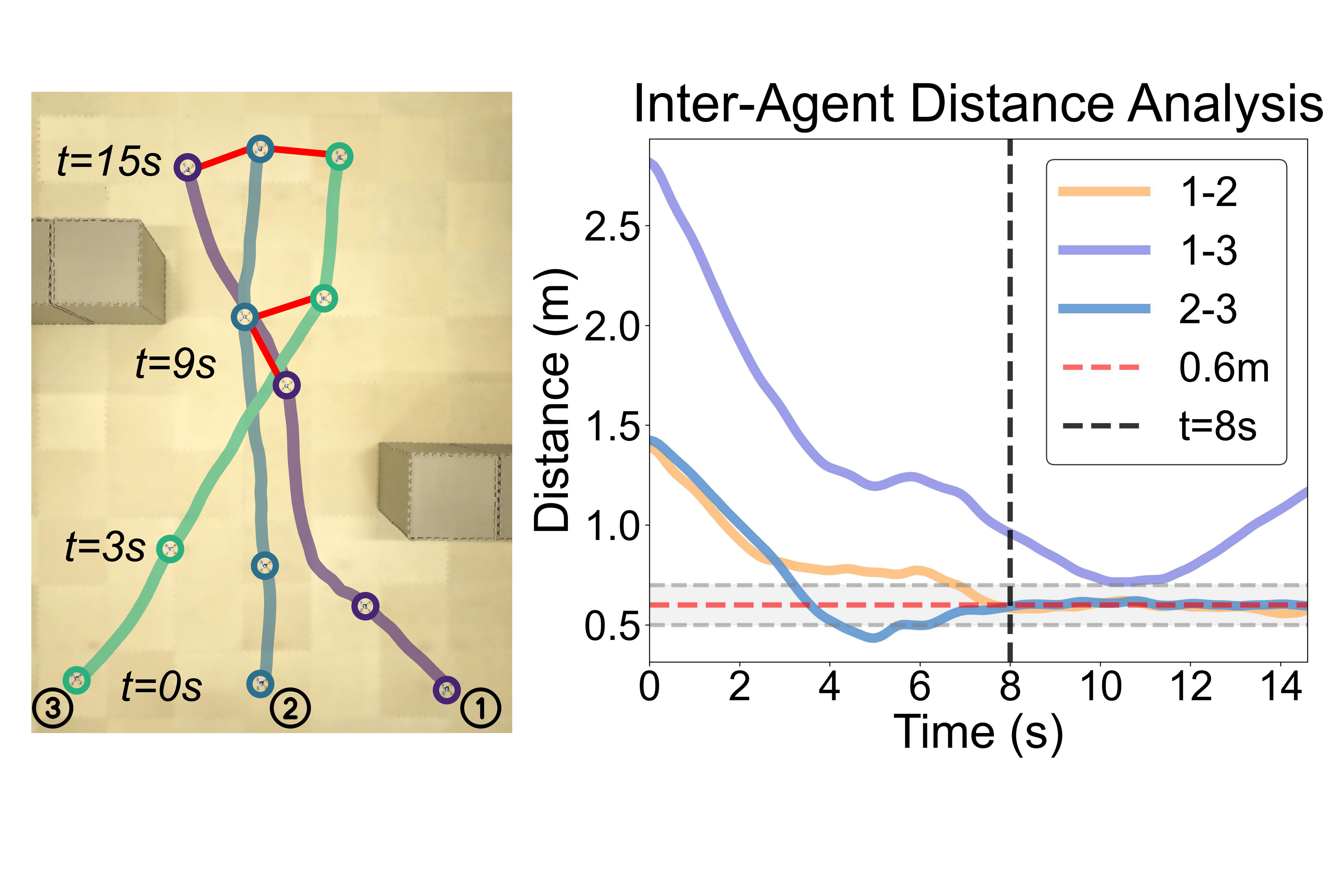
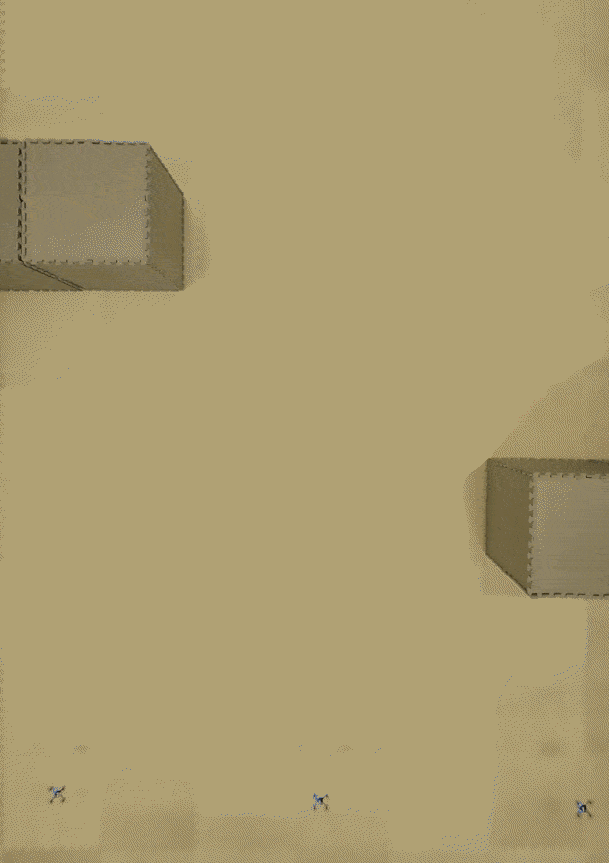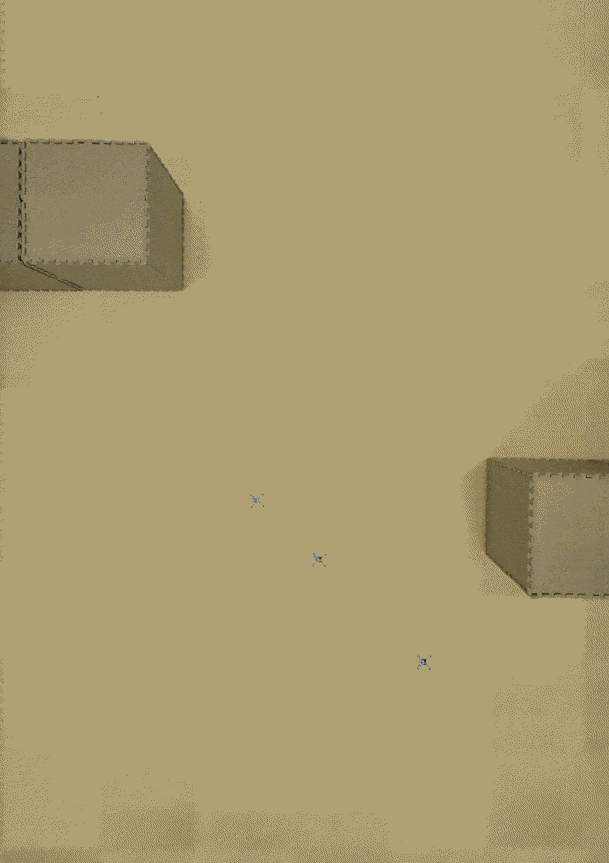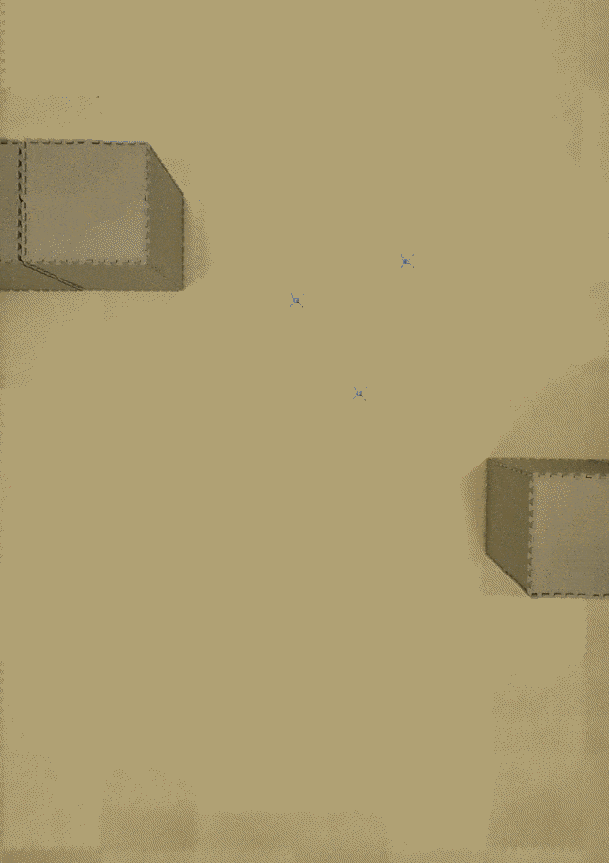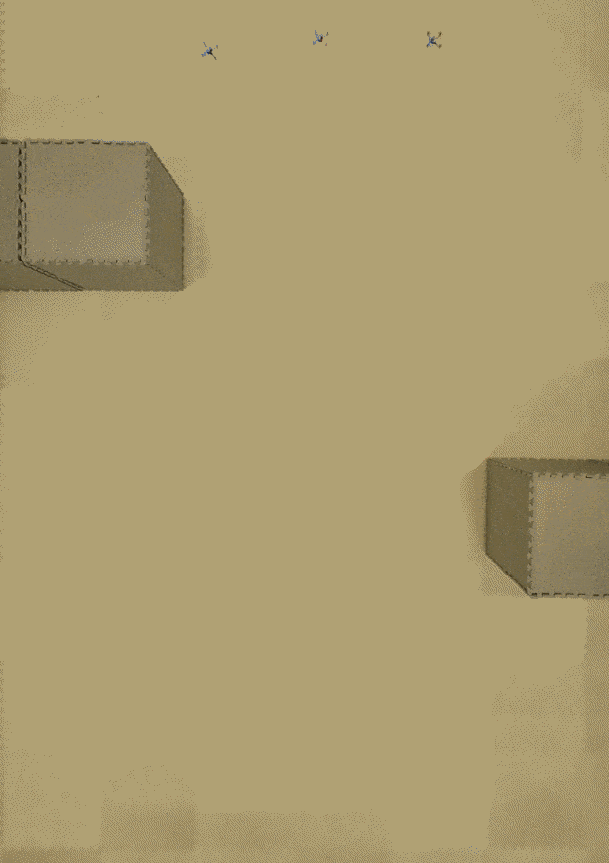
STL goal: $\varphi = \textcolor{#8a3f9c}{G}_{\textcolor{#2f7d8a}{[8,15]}}\,\textcolor{#557a3a}{\mu_{B}}$. Always between $t=8$ and $t=15\,\text{s}$, maintain the linear formation.
Finite temperature turns the same kernel into an online control loop.
The idea: a graph becomes a loop
- The candidate object is a control rollout, not an edge.
- Tensorized MuJoCo-XLA rollouts, batched with
vmap. - The reducer is a finite-temperature Gibbs expectation (weight each rollout by $e^{-\text{cost}}$, then average), not a hard min.
Same Generate·Score·Reduce as GTMP, now replanning every step instead of building one graph.
Two Boltzmann reducers at two temperatures, convexly mixed.

Roll out
$B$ control sequences of horizon $H$, scored by a black-box simulator in parallel.
Then mix
Each component is a Gibbs measure $\pi_\bullet\propto e^{-J/\eta_\bullet}$ (its weights $p_{\eta_\bullet}=\nabla_v R_{\eta_\bullet}$), so the convex mix is again a valid distribution. $\beta$ is one knob from exploit (cold $\eta_{\text{loc}}$) to explore (warm $\eta_{\text{glb}}$).
Both reducers are $\nabla R_\lambda$ from the temperature family: expectation is just soft-min, differentiated.
The expectation reducer explores where MPPI and OpenAI-ES stall.



Same batch budget, same hardware. The reducer's temperature decides how much of the space the rollouts actually see. Demonstrated across in-hand cube, G1 whole-body, and crane.
The same expectation reducer closes a contact-rich loop on real hardware.

From XLA rollouts to a real robot
- The Boltzmann expectation reducer runs unchanged on hardware, replanning every step.
- JAX/XLA-parallel sampling-based MPC over a high-fidelity MuJoCo MJX model.
- Structured global sampling beats unimodal CEM / MPPI / PS on multimodal, contact-rich manipulation.
- Domain randomization runs online, inside the MPC sample budget; contact-initiation parameters give interpretable adaptation signals.
Real-world evidence that high-entropy batched rollouts survive the sim-to-real gap, not just simulation.
Guidance is a score-function reducer, the warm end of the family.
Denoise, then guide
- $D_\theta$: learned prior, the Generate stage.
- $\nabla_z J$: guidance, the score-function Reduce.
- $B_\psi$: maps control latents to a smooth B-spline trajectory (learnable knots), so guidance acts on $C^2$, dynamically feasible curves.
The per-step $-\nabla_z J$ is the score $\nabla_z\log p(z)$ of the Boltzmann target $p\propto e^{-J}$ (the normalizer drops out). In plain terms, it points the way that most lowers cost. This is the warm, score end of the temperature continuum.
One vectorizable kernel, generalized: five planners on a single temperature axis.

The same design move every time: make the algorithm the vectorizable object. Generate·Score·Reduce is just the algebra that turns the knob.
Four rules I keep returning to.
Generate many · Score in batch · Reduce with structure
- Expose the independent work early.
- Replace pointer-chasing control flow (classical OMPL-style search) with dense algebra.
- Treat diversity and optimality as different compute allocations.
- Make the proof object match the compute object.
What this is not
- Not “GPU everywhere.”
- Not abandoning geometry or proofs.
- Not claiming one planner wins everywhere.
It is a way to design algorithms whose bottlenecks are visible, measurable, and schedulable.
A planner can be compiled into a heterogeneous robotics stack.
The same plan flows across three schedulers: the right allocation of algorithm to computing hardware.
Where I hope this community pushes next.
Lazy tensor graphs with guarantees
Skip most edges while proving homotopy-critical edges survive.
Class-aware extraction
If the graph contains many route families, enumerate them deliberately.
Connector-aware scheduling
Adapt $(M,N,s)$ online from measured $\bigl(q_s,\Lambda_s\bigr)$ profiles.
Compiler / runtime co-design
Should planners ship as XLA / JAX programs? Benchmark homotopy coverage and compute efficiency, not only first-solution time.
These are algorithm, architecture, and systems questions, not only motion-planning questions.
Parallelism is a design constraint, not an implementation detail.
The next planning algorithms will be judged by the workloads they can handle, not only the paths they return.
Most results here are large-batch simulation studies; the 3-UAV flight is the hardware validation. Large-batch simulation is what makes batched planning measurable.
the structure was hiding in plain sight.
Thank you
